Como mantenedor del popular módulo de contribución D8 Migrate Source CSV, ya era tiempo de que escribiera como funciona. Es similar a una migración del core, exceptuando el hecho de que se debe crear con anticipación los nodos de destino, taxonomías, etc. Voy a usar un ejemplo sencillo en esta publicación de una persona que está destinada a aterrizar en un nodo de tipo Persona relacionado con una taxonomía de País.
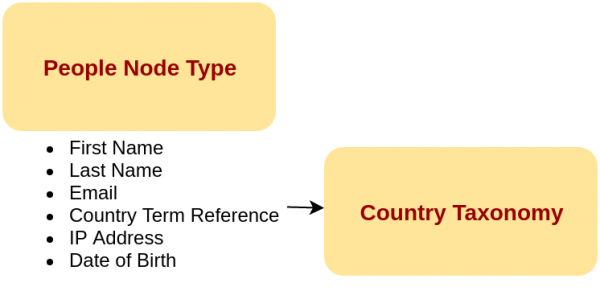
Entonces, empezaremos construyendo el tipo de nodo Persona y la taxonomía relacionada a este. Cuando termine de crearlos regrese y continuaremos con la migración de CSV. Ok, ya esta de vuelta? Genial. Entremos en la migración.
Las migraciones en D8 siguen un proceso de 3 pasos. Recopilar los datos, ajustar/manipular los datos, a continuación, guardar los datos en un destino.
- Recopilar = Source plugin
- Ajustar/Manipular = Process plugin
- Guardar = Destination plugin
Afortunadamente, alguien ya escribió todos estos plugins para usted. Algunos de estos están en el core y algunos se encuentran en diferentes módulos de contribución. Sólo tiene que conectarlos en un archivo de migración .yml
El archivo .yml se parece a todos los demás archivos .yml en Drupal 8. Así que (debe estar) familiarizado con él por ahora. Si no es así, esta es su oportunidad para familiarizarse con .yml.
He aquí un extracto súper simple de source:
source:
plugin: csv
path: public://csv/people.csv
header_row_count: 1
keys:
- id
column_names:
0:
id: Identifier
1:
first_name: First Name
Aquí un extracto simple de proceso:
process:
type:
plugin: default_value
default_value: people
title: first_name
Aquí un extracto de destino:
destination:
plugin: entity:node
Vamos a romper cada una de las secciones más abajo. La sección de source tiene un par de partes móviles. Sin embargo, su objetivo principal es proporcionar una lista de todos los nombres de las cosas disponibles de source . Para una migración CSV, asigna el número de columna a un machine_name y un nombre descriptivo. Otro propósito de source es proporcionar una manera de eliminar la ambigüedad de una fila de CSV de otra, por lo que no se vuelvan a importar lo mismo varias veces. Por último, tenemos que proporcionar configuración para el plugin CSV para que pueda encontrar y leer el archivo.
- plugin: csv => El source plugin ID que deseamos usar.
- path: public://csv/people.csv => El Path donde el csv esta situado.
- header_row_count: 1 => ¿Cuántas líneas saltar al comienzo del CSV porque se consideran la fila (s) de cabecera.
- keys => Una matriz(array) yaml de nombres de las columnas que hacen la fila única, para que no vuelva a importar lo mismo varias veces.
- column_names => Matriz(array) númerica indexada yaml de nombres de las columnas.
- file_class, delimiter, enclosure, escape => Opciones avanzadas de configuración a las que cuales no recurriré. Leer la definición de esquema para ellos en el módulo de migrate_source_csv en config / schema / migrate_source_csv.source.schema.yml
A continuación, la sección de proceso. Aquí es donde pasamos la mayor parte de nuestro tiempo, mapeando los datos desde el origen hasta el destino. Hay varios plugins de proceso ya construidos para usted en el núcleo y en módulo de contribución. Deberá combinarlos para ajustar sus datos en un formato adecuado para la inserción en el destino.
He aquí un fragmento más completo y ligeramente más complejo del proceso:
process:
# The content (node) type we are creating is 'people'.
type:
plugin: default_value
default_value: people
# Most fields can be mapped directly - we just specify the destination (D8)
# field and the corresponding field name from above, and the values will be
# copied in.
title:
plugin: concat
source:
- first_name
- last_name
delimiter: ' '
field_first_name: first_name
field_last_name: last_name
field_email: email
field_country:
plugin: entity_generate
source: country
field_ip_address: ip_address
field_dob:
plugin: format_date
from_format: 'm/d/Y'
to_format: 'Y-m-d'
source: date_of_birth
Para los valores donde hay una estrecha asignación uno a uno con ningún ajuste en los datos, sólo tenemos que mapear los valores. Si no podemos hacer correspondencias sobre los valores, entonces tenemos que manipular los datos en ruta desde el origen al destino. Si viene de hacer esto en D7, aquí es donde se *habría* hecho un montón de codificación php en prepareRow (). Bueno, todavía se puede enganchar en eso ... pero el 98% de las veces, usted puede hacerse cargo de los datos con los plugins de proceso disponibles. Vamos a romper los plugins proceso más complicado anteriormente.
Default value: Esto hace lo que se podría pensar que hace. Proporciona un valor predeterminado. En nuestro caso, se establece el paquete al nodo Personas.
Concat: Esto también hace lo que se podría pensar. Se encadena dos o más valores junto con un delimitador opcional.
Entity generate (migrate_plus): Éste es bastante complicado bajo el capó. Mantiene las cosas simples, le permite generar un término de taxonomía (o cualquier otra entidad) si la entidad no existe. Si existe, la utiliza. En cualquier caso, el valor de retorno de 'entity_generate' es un identificador de entidad para almacenar en un campo de referencia de la entidad. Esto se hace analizando el campo de destino de referencia de la entidad y la ejecución de una consulta de base de datos para ver si existe un término (o nodo) con el nombre / título, siempre a partir del valor de origen. Voy a suponer que hay más poder en este plugin, por lo que recomiendo sea leído su doxygen y ver lo que el y su hermana 'entity_lookup' pueden hacer con varios parámetros opcionales.
Format date (migrate_plus): No hay ningún plugin de proceso formato de fecha en el núcleo, así que añadí uno a migrate_plus para los efectos de esta publicación. Se pasa este plugin del formato de origen y el formato de destino y el resto se transforma mediante las funciones de fecha de PHP. He explorado brevemente usando el callback process plugin, pero con este plugin, no se puede pasar ningún argumento adicional a él. Así que he construido un plugin de formato de fecha contrib.
La última parte de un yaml de migración es el destino. Poner un destino en el yml y todo está listo.
Aquí está una copia completa de una migración entera de archivo yml. Y si quieres ver todo el código, también he vinculado un proyecto de ejemplo completo en las referencias. Analizar específicamente web / modules / custom / custom_migrate / config / install / migrate_plus.migration.migrate_csv.yml. El ejemplo fue construido con drupalvm. Todo lo que tiene que hacer para usarlo es ejecutar vagrant up y drush @ d8-custom-migrate.dev mi --all
uuid: 5c12fdab-6767-485e-933c-fd17ed554b27
langcode: en
status: true
dependencies:
enforced:
# List here the name of the module that provided this migration if you want
# this config to be removed when that module is uninstalled.
module:
- custom_migrate
# The source data is in CSV files, so we use the 'csv' source plugin.
id: migrate_csv
label: CSV file migration
migration_tags:
- CSV
source:
plugin: csv
# Full path to the file.
path: /artifacts/people.csv
# The number of rows at the beginning which are not data.
header_row_count: 1
# These are the field names from the source file representing the key
# uniquely identifying each game - they will be stored in the migration
# map table as columns sourceid1, sourceid2, and sourceid3.
keys:
- id
# Here we identify the columns of interest in the source file. Each numeric
# key is the 0-based index of the column. For each column, the key below
# (e.g., "start_date") is the field name assigned to the data on import, to
# be used in field mappings below. The value is a user-friendly string for
# display by the migration UI.
column_names:
# So, here we're saying that the first field (index 0) on each line will
# be stored in the start_date field in the Row object during migration, and
# that name can be used to map the value below. "Date of game" will appear
# in the UI to describe this field.
0:
id: Identifier
1:
first_name: First Name
2:
last_name: Last Name
3:
email: Email Address
4:
country: Country
5:
ip_address: IP Address
6:
date_of_birth: Date of Birth
process:
# The content (node) type we are creating is 'people'.
type:
plugin: default_value
default_value: people
# Most fields can be mapped directly - we just specify the destination (D8)
# field and the corresponding field name from above, and the values will be
# copied in.
title:
plugin: concat
source:
- first_name
- last_name
delimiter: ' '
field_first_name: first_name
field_last_name: last_name
field_email: email
field_country:
plugin: entity_generate
source: country
field_ip_address: ip_address
field_dob:
plugin: format_date
from_format: 'm/d/Y'
to_format: 'Y-m-d'
source: date_of_birth
destination:
# Here we're saying that each row of data (line from the CSV file) will be
# used to create a node entity.
plugin: entity:node
# List any optional or required migration dependencies.
# Requried means that 100% of the content must be migrated
# Optional means that that the other dependency should be run first but if there
# are items from the dependant migration that were not successful, it will still
# run the migration.
migration_dependencies:
required: {}
optional: {}
¿Está buscando ayuda para una migración o actualización de Drupal? Independientemente de la complejidad del sitio o de los datos, MTech puede ayudarle a pasar de un CMS privado o actualizarlo a la última versión: Drupal 8.
Escríbanos sobre su proyecto y nos pondremos en contacto con usted dentro de 48 horas.